大數據技術基石 Hadoop數據處理服務全解析
在當今數據爆炸的時代,如何高效地存儲、處理和分析海量數據已成為各行各業面臨的核心挑戰。Hadoop,作為大數據技術領域的基石,憑借其分布式、可擴展、高容錯的特性,為大規模數據處理提供了成熟可靠的解決方案。本文將系統介紹Hadoop的核心架構、關鍵組件及其數據處理服務。
一、Hadoop概述:分布式計算的革命
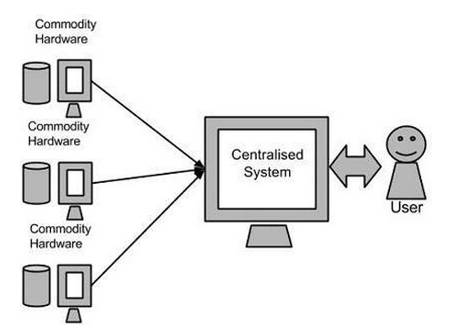
Hadoop是一個由Apache基金會開發的開源分布式計算框架,其設計靈感來源于Google的MapReduce和Google File System(GFS)論文。它能夠在由普通商用服務器組成的集群上,對海量數據集進行分布式處理。Hadoop的核心優勢在于其高可靠性(數據自動備份)、高擴展性(可輕松擴展至數千節點)和高容錯性(任務失敗自動重新分配)。
二、Hadoop核心架構:兩大支柱
Hadoop生態系統主要由兩大核心組件構成:
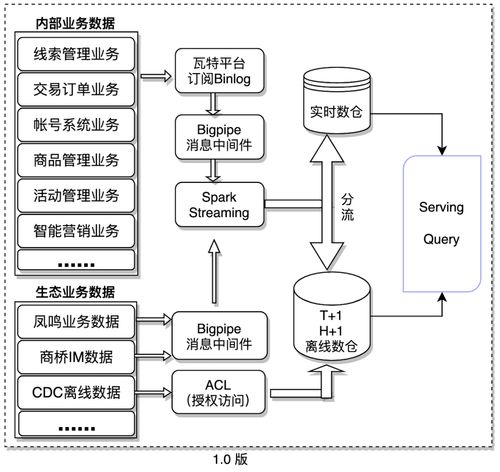
1. HDFS(Hadoop Distributed File System)
HDFS是Hadoop的分布式文件系統,負責數據的存儲。它將大文件分割成多個塊(默認128MB),并分散存儲在不同節點上,每個數據塊會復制多份(默認3份)存儲在不同節點以確保容錯。HDFS采用主從架構:
- NameNode:主節點,管理文件系統的命名空間(如目錄樹、文件元數據)和數據塊映射。
- DataNode:從節點,負責存儲實際的數據塊,并定期向NameNode報告狀態。
2. MapReduce
MapReduce是Hadoop的分布式計算框架,負責數據的處理。它將計算任務抽象為兩個階段:
- Map(映射)階段:將輸入數據分割成獨立的片段,由多個Map任務并行處理,生成一系列中間鍵值對。
- Reduce(歸約)階段:將Map階段輸出的中間結果按Key進行排序和分組,然后由Reduce任務進行聚合計算,最終生成結果。
這種“分而治之”的模型,使得處理TB甚至PB級數據成為可能。
三、Hadoop生態系統:豐富的數據處理服務
圍繞HDFS和MapReduce,Hadoop已發展出一個龐大而成熟的生態系統,提供了全方位的數據處理服務:
- 數據存儲與管理
- HBase:基于HDFS的分布式、面向列的NoSQL數據庫,適合實時讀寫和海量數據存儲。
- Hive:數據倉庫工具,提供類似SQL的查詢語言(HiveQL),將查詢轉換為MapReduce任務,降低使用門檻。
- 數據采集與傳輸
- Flume:高可用的分布式海量日志采集、聚合和傳輸系統。
- Sqoop:用于在Hadoop和結構化數據存儲(如關系型數據庫)之間高效傳輸數據的工具。
- 資源管理與調度
- YARN(Yet Another Resource Negotiator):Hadoop 2.0引入的核心組件,負責集群資源管理和作業調度。它將資源管理與作業監控分離,使得Hadoop可以運行除MapReduce之外的計算框架(如Spark、Tez),大大提升了集群利用率和靈活性。
- 高級計算框架
- Spark:基于內存的分布式計算框架,速度比MapReduce快數十倍,支持流處理、機器學習和圖計算。
- Flink:主打流處理的分布式計算框架,提供高吞吐、低延遲的精確數據處理。
- 數據協調與工作流
- ZooKeeper:分布式協調服務,用于維護配置信息、命名服務、分布式同步和集群管理。
- Oozie:工作流調度系統,用于管理和協調Hadoop作業。
四、Hadoop數據處理流程示例
一個典型的Hadoop數據處理流程可能如下:
- 數據攝入:通過Flume收集日志數據,或通過Sqoop從數據庫導入數據,存入HDFS。
- 數據存儲:原始數據以文件形式存儲在HDFS中;如需快速查詢,可將部分數據導入HBase。
- 數據處理:開發MapReduce程序,或使用Hive編寫SQL進行離線批處理分析;對于實時性要求高的場景,使用Spark Streaming或Flink進行流處理。
- 資源調度:所有計算任務由YARN統一分配集群資源(CPU、內存)。
- 結果輸出:處理結果寫回HDFS,或導入數據庫供前端應用展示。
五、Hadoop的應用場景與未來
Hadoop廣泛應用于互聯網搜索、電商推薦、金融風控、電信用戶行為分析、生物信息學等領域。盡管如今Spark等更快的計算框架日益流行,但HDFS作為可靠的分布式存儲層,以及YARN作為資源調度器,仍然是許多大數據平臺不可或缺的組成部分。Hadoop將繼續與云原生、容器化技術融合,并在存算分離、彈性伸縮等方面持續演進,鞏固其作為大數據基礎設施的核心地位。
Hadoop不僅是一套技術,更是一種處理海量數據的哲學。它通過將數據和計算分布到廉價硬件上, democratize了大數據能力,為企業和組織從數據中挖掘價值奠定了堅實的基礎。
如若轉載,請注明出處:http://www.cn07.com.cn/product/3.html
更新時間:2026-06-19 19:10:18